Learnable Limits of Algorithms
Our use of the discrete observational grid $\mathcal{G}$ essentially lumps together all captures within one cell
(see paper for more details).
This limits the algorithm's ability to learn the true $K.$
To account for this more accurately, we can modify our definition of regret metric (formula (6) in the paper) and measure the regret relative
to the best path learnable on the specific $\mathcal{G}$. Below we provide additional tests illustrating this idea for Alg-PC and data showing
that this subtlety is laregly irrelevant for Alg-GP.
Alg-PC (piecewise constant model)
We define $\tilde{K}_*(\mathbf{x})$ to be the cell-averaged version of $K.$ This piecewise-constant function also represents the best approximation of $K$ that we could hope to attain with infinitely many captures in every cell. Computing the viscosity solution to $| \nabla \tilde{u}_* | = \tilde{K}_*,$ we obtain the $\mathcal{G}$-optimal feedback control $\tilde{\mathbf{a}}_* = -\nabla \tilde{u}_* /|\nabla \tilde{u}_*|$ and can compute its actual quality $w(\mathbf{x})$ by integrating the true $K$ over the paths resulting from $\tilde{\mathbf{a}}_*$. The corresponding capture probability is then $\tilde{W}_* = 1 - \exp( - w(\mathbf{x}_0))$ and we can define the $\mathcal{G}$-adjusted regret by using $\tilde{W}_*$ instead.
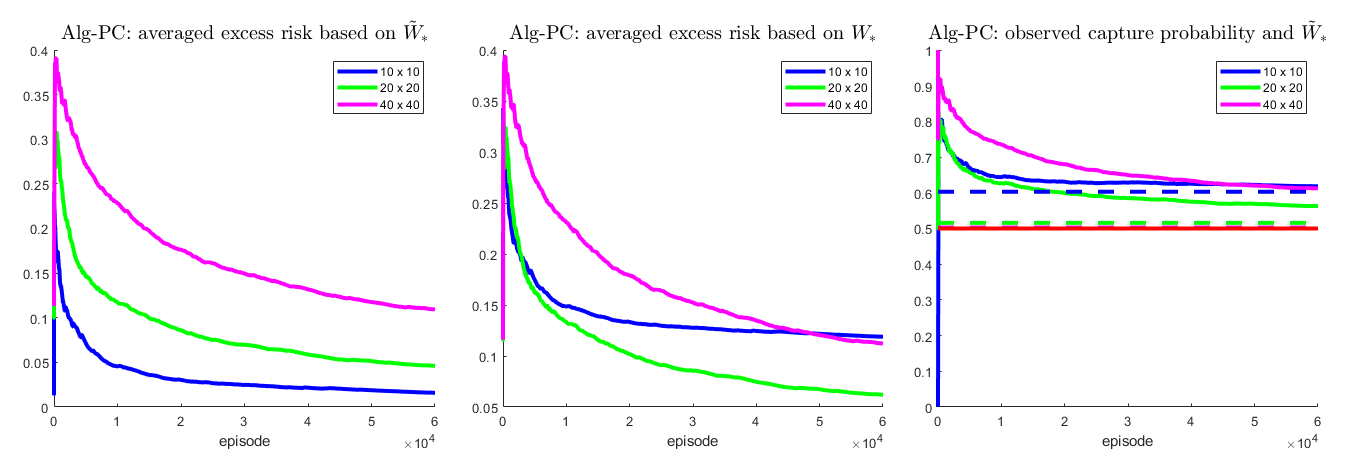
The first (left) figure below shows the new regret defined as above for different sizes of $\mathcal{G}$, applying Alg-PC to the 2nd example in paper. It illustrates that finer $\mathcal{G}$ requires more episodes to approach the asymptotic learnable limit. But even though the $20 \times 20$ $\mathcal{G}$ results in a higher grid-adjusted regret than the $10 \times 10$ grid, this is is not the case for the regret-against-the-truly-optimal-$W_*$, as defined in the paper and illustrated in the second (center) figure below. The third (right) figure illustrates the experimentally observed capture rate, together with $\tilde{Q}_*$ (dashed lines) for different sizes of $\mathcal{G}$. We observe that $\tilde{W}_*$ becomes closer to the true optimal $W_*$ (the red horizontal line) as $\mathcal{G}$ becomes finer. But it takes about $50,000$ episodes until the asymptotic advantage of the $40 \times 40$ grid yields a lower capture rate than on the $10 \times 10$. In this example, the $20 \times 20$ grid generates much smaller regrets than the other two grids.
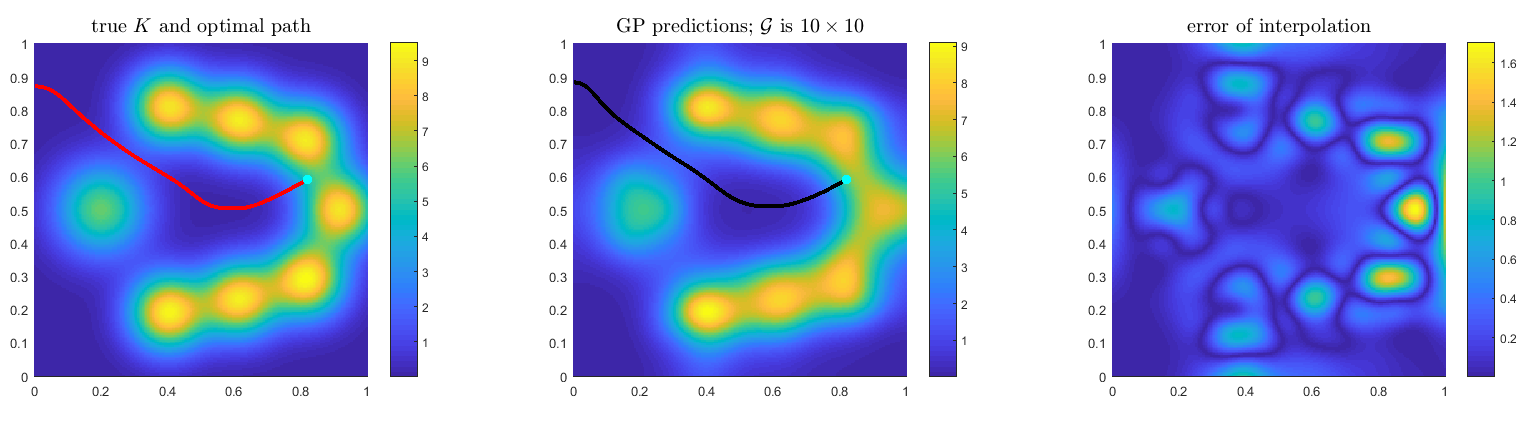
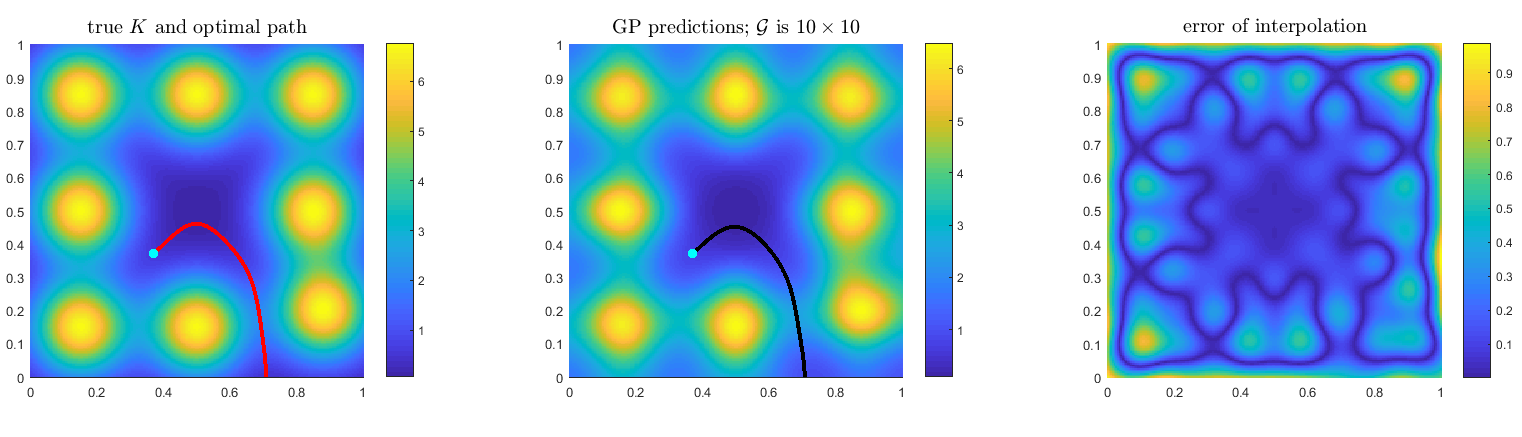
Alg-GP (Gaussian process model)
Gaussian process regression performs surprisingly well in recovering the optimal path, even on a coarse grid. For all examples considered in the paper, $\tilde{W}_*$ is already within 0.25% from the truly optimal $W_∗$ even with a coarse 10 × 10 observation grid.
The following is an illustration of this phenomenon using the 2nd & 3rd example in the paper.